法安网内容检索
法安网内容检索
.jpg)
.jpg)
.jpg)
.jpg)
时间:2019-10-10 14:54:18 来源:金鹏电子信息机器有限公司
[法安导读] 1 深度卷积神经网络解决视频图像识别目前深度学习网络有很多种架构,有基于自编码器的架构,基于玻尔兹曼机的架构以及基于卷积神经网络的 

1.深度卷积神经网络解决视频图像识别目前深度学习网络有很多种架构,有基于自编码器的架构,基于玻尔兹曼机的架构以及基于卷积神经网络的架构等。其中基于卷积神经网络的深度卷积神经网络(DCNN),已成为当前语音分析和图像识别领域的研究热点。 它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。为此,可以采用深度卷积神经网络解决视频图像识别问题。
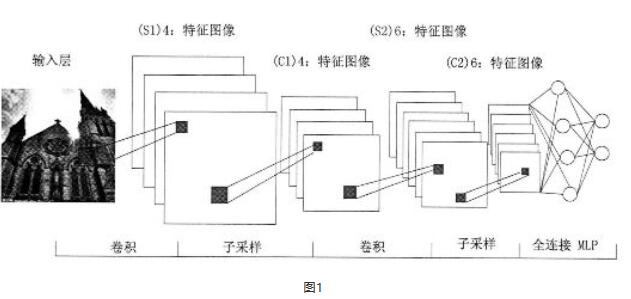
(1)深度卷积神经网络的模型
上图1为深度卷积神经网络模型图,卷积神经网络与传统的神经网络一样,拥有输入层、隐含层和输出层。其中它的隐含层包括低隐含层和高隐含层,低隐含层由卷积层和下采样层交替成对组成;高隐含层是与传统神经网络隐含层类似的全连接层。 输出层是一个分类器,可以用采集逻辑回归、softmax 回归或者支持向量机等对图像进行分类。
(2)卷积层
卷积神经网络主要是通过“局部感知野”和“权值共享”两个理论来降低网络模型复杂度、减少权值数量。
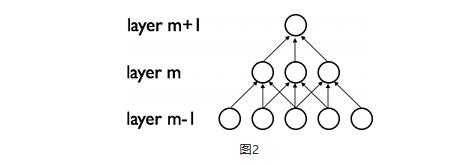
“局部感知野”是1962年Hubel和Wiesel通过对猫视觉皮层细胞的研究提出来的概念。一般认为,视觉皮层的神经元就是局部接受信息的(即,这些神经元只响应某些特定区域的刺激)。同理,人们推断图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,人工神经网络中,每个神经元其实没有必要对全局图像进行感知,只需要如下图2所示,对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。
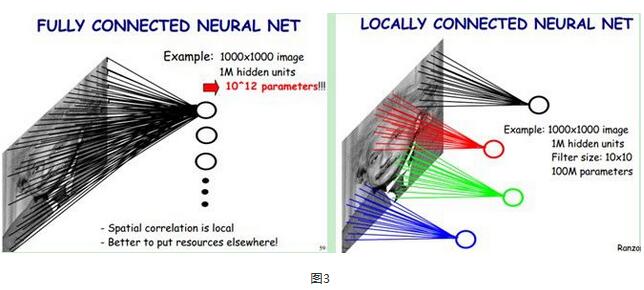
采用局部感知区域为10*10的方法,可以将1000*1000像素图像每层之间1012个全连接参数降低至108个局部连接参数。如下图3所示:左图是全连接,右图是局部连接。
“权值共享”是指图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。 在局部连接的神经网络中, “权值共享” 意味着让所有的局部感知区域的权值一致。采用权值共享的方法,可以将1000*1000像素图像每层108个局部连接的参数降低至100个局部连接共享参数。
通过卷积的方式实现“局部感知野”和“权值共享”的神经网络就是卷积神经网络。
(3)下采样层
卷积神经网络在通过卷积获得了特征之后,还需要再添加一个下采样层与之配对。这是因为卷积一个大图像(例如1000*1000)得到的特征向量维数将会非常大,容易出现过拟合。 下采样层通过对不同位置的特征进行聚合统计(例如,计算图像一个区域上的某个特定特征的平均值或最大值),不仅保留了有用信息,同时可以降低数据量、改善结果(不容易过拟合),更重要的是能够保持某种不变性(旋转、平移、伸缩等)。
由于图像的识别特征具有层次性(具有“像素-低级特征-对象部分-对象”的层次结构),其中低层图像特征具有较低的抽象性,高层图像特征具有较高的抽象性,通过组合底层特征能够形成更加抽象的高层表示。因此本项目将建立一种含有四对“卷积层-下采样层”的深度卷积学习模型。其中卷积核大小和卷积核数将会根据实际数据进行对比测试确定,输出层采用的分类模型将会根据采集逻辑回归、softmax回归以及支持向量机的具体表现进行抉择。
2.基于深度卷积网络的图像目标检测分类算法基于深度卷积网络的图像目标检测分类,常用的算法包括:R-CNN,SPP-NET、FASTR-CNN、FASTERR-CNN、YOLO、SSD等。
2013年,Ross提出了 R-CNN(Regioncnn,基于区域的卷积神经网络)的模型方法,采用对 Region proposal(区域候选)提取CNN特征。R-CNN的目标检测主要方法包括采用回归目标窗口和滑动窗口,它的主要测试过程如下:
给定一张图片,利用 selective search方法来产生2000个候选窗口。
利用CNN进行对每一个候选窗口提取特征,特征长度为4096维度。
最后用SVM分类器对这些特征进行分类(每一个目标类別一个SVM分类器)。
但是R-CNN的计算时间太长,重复计算太大,因此微软亚洲研究院何凯明等人在R-CNN的基础上提出了 SPP-NET(Spatial Pyramid Pooling-Net,空间金字塔池化网络)的模型架构,SPP-NET主要是修改了最后一层卷积层后的最大池化层,将其用空间金字塔池化层代替,这样做的好处在于首先对输入图像尺度无限制,同时输出的是定长特征,但运用滑动窗口的池化技术就无法达到这样的效果;其次SPP可运用不同大小的池化窗口,但CNN只能是单一的窗口;接着SPP可从尺度变化中提取特征;另外可以大大提高了图像处理速度,是R-CNN方法的24-102倍。
尽管如此,SPP-NET仍旧存在缺陷:
一是SPP-NET虽然极大地提高了R-CNN的速度,但和R-CNN一样,他们的训练过程都是一个多阶段过程:即包含着特征抽取,网络徹调,分类器SVM的训练及最后的对 BoundingBox(边界框)回归器的匹配。
二是SPPNET中用到的微调技术只能更新FC层,这无疑限制了深度CNN的潜力。
FAST-R-CNN(fast region CNN,快速区域的卷积神经网络)是在R-CNN和SPP-NET基础上提出的一种利用深度卷积神经网络对快速检测目标的方法。由于R-CNN和SPPNET共同存在以下缺点,
1.训练的时候传递途径是隔离的,即首先提取候选框,然后利用CNN提取特征,之后用SVM分类器,最后再做边界框的回归。而FASTR-CNN实现了端对端的联合训练。2.训练时间和空间开销大。R-CNN中ROl-centric的运算开销大,所以FASTR-CNN用了图像中心的训练方式来通过卷积的共享特性来降低运算开销;R-CNN提取特征给SVM训练的时候需要大量的磁盘空间存放特征,FAST-R-CNN去掉了SVM这一步,所有的特征都暂时存储于显存中,不需要额外的磁盘空间。3.测试时间开销大。依然是因为ROI的原因,这点SPP-NET己经改进,然后FASTR-CNN进一步通过单尺度测试和SVD分解全连接来提升速度。
3.面向时空关联语义分析的多源数据融合模型视频内容的识别和理解是实现智慧型应用服务的关键技术点。 传统的识别方法通常针对单一的分析源中的颜色、形状、运动轨迹等特征进行分析。这样的分析结果往往导致本身存在强关联的对象之间的关系无法建立,从而丢了视频中本身包含的大量潜在信息。
通过对多种关联数据进行分析,可以挖掘出更有价值的应用,例如刑侦线索分析、案件规律分析、社会舆情分析、金融诈骗分析、公共交通优化等。如何对这些海量的融合数据进行清洗和选择,并建立有效的分析模型是一个有趣的挑战。因此,本项目将采用多源数据融合的方式实现多通道、全时空的语义分析。
多源数据融合可以分为3种思路与方法:
数据层融合。先对各模态的视频数据进行简单组合形成新的特征向量,再进行后续的常规分类或识别等过程.
特征层融合。从单模态视频数据中提取有效互补的特征,通过时间尺度等规则将这些特征有机结合在一起,作为统一的多模态数据特征。
决策层融合。从不同模态的视频数据中分别提取特征,通过模式识别过程获得识别结果与权重,在通过融合策略获得最后的判别或者识别结果。
与传统基于单源数据的方法相比,多源数据融合把多个数据源在时间和空间上冗余或互补的信息依据某种准则进行组合,获取被观测对象的一致性解释或描述,以便能够扩展时空的覆盖范围,减少信息的模糊性,增加对目标行为确认的可信度,改善系统的可靠性。尤其系统借助GIS 独特的地理空间分析能力、快速的空间定位搜索和复杂的查询功能、强大的图形处理和表达能力,可以直观地在地图上显示各个摄像头的位置,在事件发生时也会根据摄像头的位置在地图上标出地点,帮助办案人员快速了解事件地点及其周边信息。
作者:曹志雷、教颖辉、冯力
编辑:广汉
声明:
本网站图片,文字之类版权申明,因为网站可以由注册用户自行上传图片或文字,本网站无法鉴别所上传图片或文字的知识版权,如果侵犯,请及时通知我们,本网站将在第一时间及时删除。

征稿启事

投稿信箱:195024562@qq.com
品牌推荐更多>>

.jpg)
.jpg)



版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号











