

也可直接联系我们
方式一 拨打报名热线或邮件咨询:
电话: 010-67046081
邮件: 195024562@qq.com
方式二 填写参会确认表
表单下载: 下载
发邮件至: 195024562@qq.com
或传真至: 010-67046081
为深化政法智能化建设,加强“智慧治理”“智慧法院”“智慧检务”“智慧警务”“智慧司法”等信息平台建设,深入实施大数据战略,实现科技创新成果同政法工作深度融合。法制日报社已连续举办了六届“政法智能化建设技术装备及成果展”。
作为装备展配套活动,法制日报社于去年3月继续举办了2023政法智能化建设创新案例及论文征集宣传活动,活动征集了“智慧治理”“智慧法院”“智慧检务”“智慧警务”“智慧司法”创新案例、方案、产品、论文,2023年6月25日结果揭晓发布。入选的各类创新案例、方案、产品、论文在2023年7月10日至11日举办的成果展上进行了集中展示,并已编辑整理成册——《2023政法智能化建设创新案例及论文汇编》。
该汇编分为智慧治理篇、智慧法院篇、智慧检务篇、智慧警务篇、智慧司法篇五个篇章,为政法信息化、智能化建设提供及时、准确、 实用的资讯信息与经验观点。
应广大读者要求,我们特开辟专栏,分别将部分创新案例、创新方案、创新产品、创新论文进行展示,敬请关注!
以下推出的是《智慧司法篇 | 创新论文之“基于XGBoost的新型社矫人员再犯罪预测技术研究初探”》

基于XGBoost的新型社矫人员再犯罪
预测技术研究初探
——以H省司法厅为例
周鸿明 韩冬 杜宏钢 王巍 玄世昌
黑龙江省司法厅
摘要:社区矫正是一种非监禁形式的刑罚执行方式,通过非监禁的环境改变个人恶习,使其顺利重回社会。怎样精准测定影响个体的再犯因子,以提高再犯风险评估的准确性,始终是再犯风险评估的重难点。人工智能技术能有效解决这些问题,其通过对比数据分析,得出人身危险性程度的评估结果。这也是风险评估工作发展的必然趋势。
一、研究现状
英美等国家早已开发出基于大数据算法的支持,预测个别罪犯是否有可能再犯的评估工具[i]。社区矫正人员再犯罪预测是一个二分类问题,基于决策树的各类算法[ii][iii]、k-近邻[iv]、随机森林[v]支持向量机[vi]、贝叶斯网络等[vii]是常用的分类算法,可用于解决此问题。
我国的社区矫正,是贯彻宽严相济刑事政策,是立足我国国情和长期刑事司法实践经验基础上,借鉴吸收其他国家有益做法,逐步发展起来的具有中国特色的非监禁的刑事执行制度[viii]。国内大多数地方社区矫正机构启用了智能化的信息管理系统,包括社区矫正对象电子档案及日常管理考核等,但智能化信息收集、处理和评估系统还没有完全建立起来并加以应用[ix]。因而选用合适的模型对国内的社矫人员数据进行分析进而实现再犯罪预测,有助于推进整个社矫体系的完善,有针对性的防止某些人员再次误入歧途。
二、现存问题
(一)技术问题
虽然传统机器学习方法在分类问题上已经得到了广泛应用,但是它们也存在一些问题:
1、模型易过拟合。模型在训练集上表现很好,但在测试集上表现不佳。
2、由于这些算法本质上是基于特征空间的划分,因此对于数据中的噪声很敏感,弱数据中存在大量噪声,模型的准确性将会受到较大影响。
3、需要手动设置很多参数。例如每个决策树的最大深度、每个决策树使用的特征数量等,这需要具有一定经验和专业知识的人员进行调参。
(二)应用问题
1、矫正人员再犯罪预测需要大量数据,由于此类数据涉及到个人隐私,因而现有样本较少,这也使得模型容易过拟合。
2、利用机器学习的相关算法训练模型,实现再犯罪预测是较为常见的一种方法,但大都只是理论研究,并没有针对实际数据的深入分析和实现。
三、研究内容
(一)选用模型
XGBoost算法适用于表格数据,针对由社矫人员数据形成的表格数据,XGBoost算法的预测效果表现较好。XGBoost[x]是一个加法模型,它以CART树为基学习器,通过优化传统梯度提升决策树实现多棵树的集成学习,训练方式采用前向分步算法逐步优化里面的每个基学习器,可用来解决分类、回归等机器学习问题。其中在实现多颗树的集成学习上,模型使用训练集构建一颗初始树进行训练,得到模型预测值与实际值的残差,然后在每次迭代过程中都增加一棵树来拟合模型上次预测的残差直至模型学习进程被终止,由此形成如图1所示的由众多树模型集成的迭代残差树集合[xi]。对于第i个样本的预测值为表达式(1)所示。
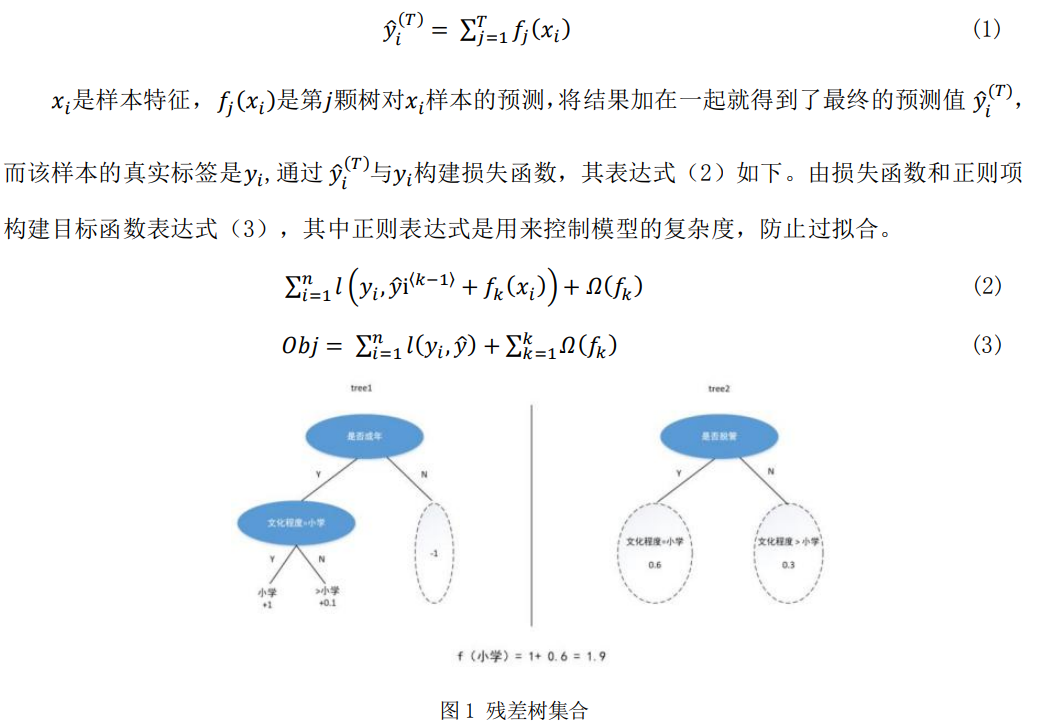
(二)社区矫正人员再犯罪预测数据
根据中华人民共和国司法行政行业标准SF/T 0015—2021版《社区矫正基础业务系统技术规范》的指示,表1展示了我们筛选出的部分对于社矫人员再犯罪预测的重要字段。
表1重要字段
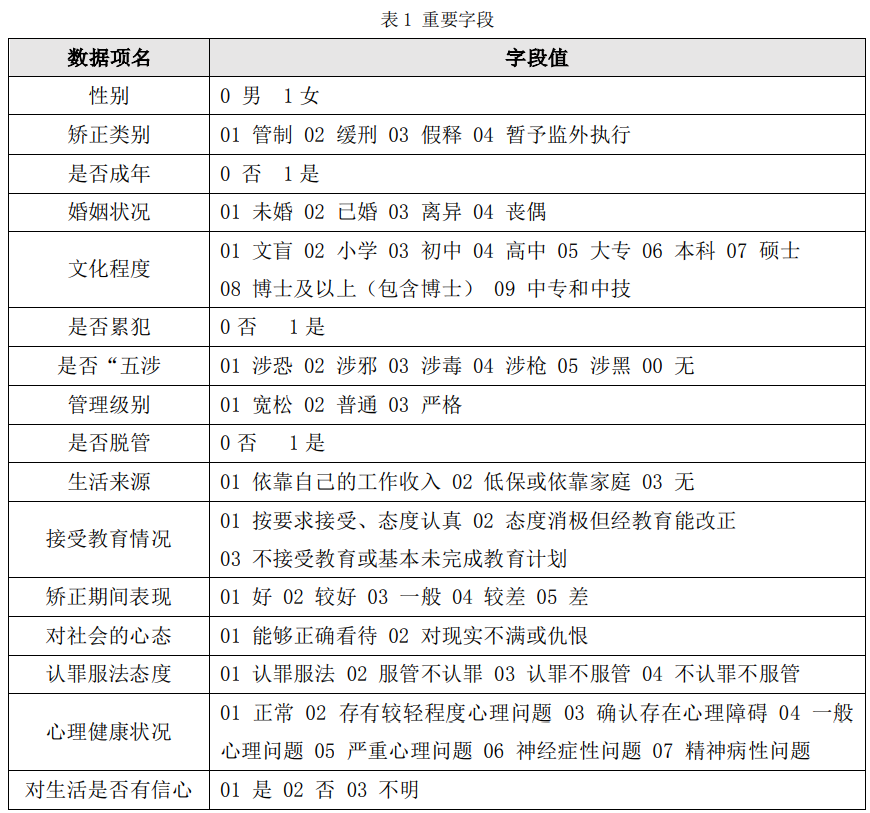
表中部分数据处理方式如下:
1.矫正类别、矫正期间表现:首先将其缺失值置为-1,将未缺失的数据作为训练集,缺失的数据作为要预测的集合,使用逻辑回归进行训练模型来预测该字段缺失值所对应的值,将预测值作为缺失值进行填充即可。
2.管理级别:采用SimpleImputer中的均值策略来填充数据中的缺失值。
3.对社会的心态:采用0值进行填充。
四、实验验证
实验由两部分组成,第一部分采用由美国政府司法部举办的再犯罪预测挑战赛所提供的数据集[1]。选取部分与社矫规范中的数据相似的字段进行实验,验证选取方法的有效性;第二部分参照社矫规范和真实案例,提取部分数据构造验证集,验证所提方法的可行性。
(一)实验一
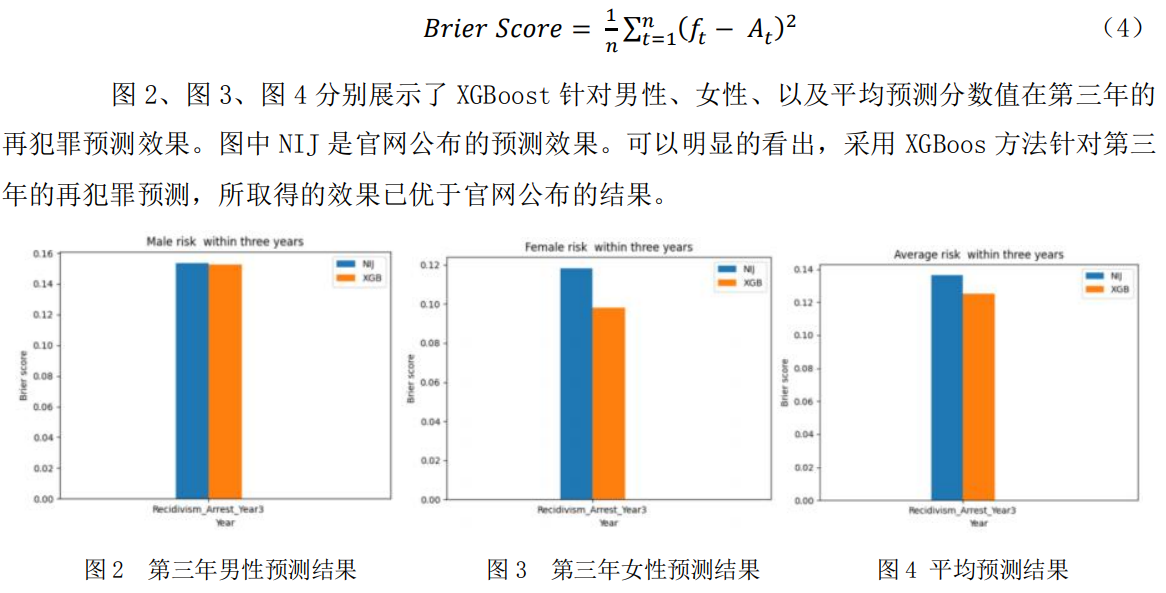
数据包含佐治亚州关于2013年1月1日至2015年12月31日期间从监狱释放到假释监督的人员的数据。参赛者需对数据集中每个人是否会在释放后三年内再次犯罪的事实进行预测。使用Brier分数来衡量预测效果,分数越低代表准确性越高。分数计算公式如(4)。
(二)实验二
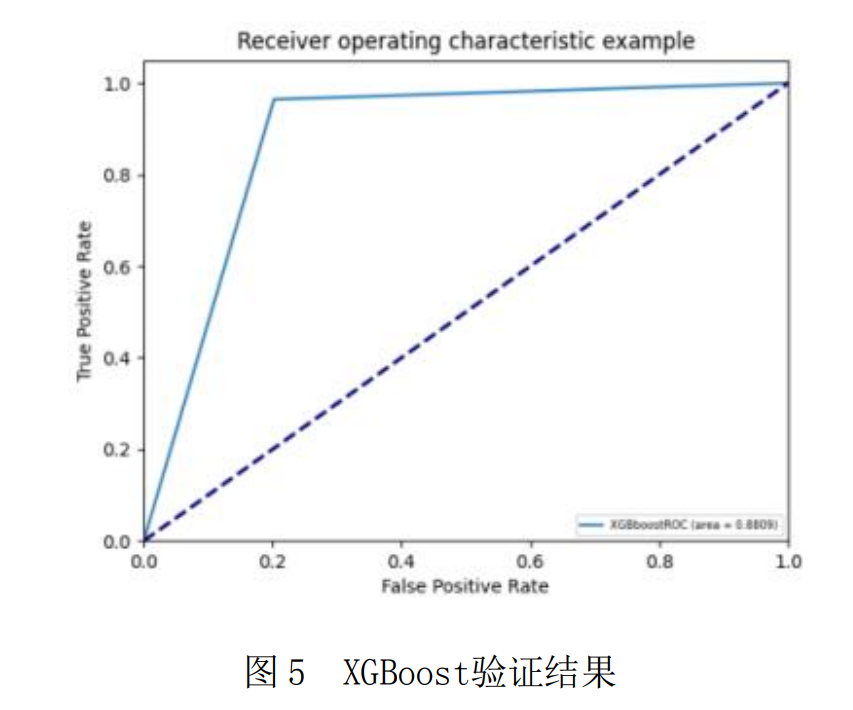
参照社矫规范和真实案例,提取部分数据构造验证集,使用XGBoost模型进行技术验证,采用ROC指标衡量验证结果。如图5所示,XGBoost验证取得的效果较好,由此证明该方法同样适用于国内的社矫人员再犯罪预测。
五、总结
本文选用XGBoost模型进行社矫人员再犯罪预测。利用历史数据和罪犯的个人信息等因素,建立一个能够准确预测罪犯再犯罪概率的模型,并且可根据管理罪犯的风险等级分配不同的管教资源,以达到更好的管教效果。此外,该模型还解决了传统机器学习方法中存在的对噪声敏感、无法处理高维稀疏数据以及需要手动调参等问题。
除了在罪犯矫正方面的应用,XGBoost还可在其他领域中发挥重要作用,如金融欺诈检测、医疗预测等。总之,随着数据的持续积累和技术的不断进步,XGBoost算法将在各个领域中得到越来越广泛的应用。
责任编辑:晓莉
版权所有:北京法安网络文化传媒有限公司
京ICP备18035954号-1
 京公网安备 11010602006854号
京公网安备 11010602006854号









